クイックのエンジニアリングブログはQiitaに移行します
クイックのエンジニアリングブログをご覧いただきありがとうございます。
突然のお知らせとなりますが、本エンジニアリングブログは更新を一旦停止し、新たな媒体としてQiitaで技術記事を更新していくことにしました。
もしクイックのエンジニアがどんな発信をしているのかということにご興味を持っていただけたのであれば、引き続きQiitaでアウトプットをしていますので、以下のリンクからご覧いただければと思います。
当ブログは2015年の開設以来、クイックでの技術・ノウハウ・チャレンジ内容を発信してきましたが、もっとアウトプットを活発にしたいということや、もっと多くの人に届けたいという動機から、新たな媒体で形を変えて発信を行っていきます。
引き続きよろしくお願いします。
暫定AWS環境からの脱却:IaC再構築によるリプレイスとデプロイの最適化
皆さんこんにちは、システム基盤を日々支えるインフラエンジニアのTOKです。
突然ですが、次のような状況に身に覚えはありませんか?
- 暫定的な環境で運用を始めたものの、拡張性やパフォーマンスが課題に。
- プロジェクトの納期が厳しく、理想的な設計を追求する余裕がない。
- 複雑なアプリケーション構成で、既存のIaC(Infrastructure as Code)ツールでは対応が難しいと感じた。
こうした問題に直面している方に向けて、この記事では私が担当したAWS暫定環境からの脱却事例と、その過程でのIaC再構築、そして運用の最適化について紹介します。 リプレイスの過程で直面した課題をどのように解決し、どんな結果を得られたのか?その詳細をお伝えします。 もし、あなたがインフラ運用やデプロイの効率化に関心があるなら、この経験がきっと役に立つはずです。それでは、具体的なプロセスを見ていきましょう。
1. 暫定的なAWS環境でのリプレイス案件
このリプレイス案件では、暫定的なAWS環境で稼働しているサービスを最終的な環境に移行する必要がありました。 通常は、既存の標準IaCツール(Itamae、Ansible、Jenkins、AWS CLI、GitLab、GitHub、Capistrano)を使用するところですが、このプロジェクトでは新たなIaC基盤の構築が求められており、また、納期が厳しい状況下でした。 そんな中で私が取った手順は以下となります。
初期フェーズにおける課題とその対応
サービス運営チームとの連携を通じて、サービスの特徴や将来的な拡張性を考慮した設計を行うのは一般的ですが、今回のプロジェクトでは納期が最優先でした。 そのため、拡張性や理想的なインフラ構成を追求する余裕がなく、迅速な対応が必要でした。
具体的には、暫定的なAWS環境から本番環境への移行において、まずはシンプルで安定した構成を優先しました。冗長化は後にして、まずは単一サーバー構成でサービスを稼働させることに注力しました。段階的に冗長化やロードバランサーを用いた複数EC2の構成を追加することで、限られたリソースと時間を最大限に活用し、短期間でサービスの安定稼働を実現しました。
新しいベース環境の構築
初期段階ではシングル構成のアーキテクチャを使用し、標準的なIaCをベースにしつつカスタムIaCを作成しました。暫定環境でシングルサーバー構成を採用し、動作が安定した後に、標準的なロードバランサーと複数台のEC2によるラウンドロビンで負荷分散を実現しました。このアプローチは、短期間での安定動作を実現するために合理的な選択でした。
冗長構成の検証
重要だったのは、アプリケーション開発者と密に協力し、冗長構成を理論上検証し、その後実際に動作確認を行うことでした。この確認はシステム全体の安定性を確保するために欠かせませんでしたし、問題なく動作することが実証できたことは、大きな成果と言えます。
ビルドフローのリプレイス
リプレイス作業中に、Amazon Linux 2023への移行時期が重なりました。この際、DockerコンテナのOSバージョンアップやCapistranoのビルド用ライブラリの更新が必要となりました。この点については「追加の工数」と捉えるのではなく、今後のプロジェクト全体に役立つテンプレート作成とリファクタリングの機会と捉え、協力会社と連携して新しいテンプレートを作成しました。その結果、生産性とメンテナンス性の向上を達成できました。
このように、一度に全体を移行するのではなく、小さなステップを踏むことで、プロジェクトの安定性を保ちながらリプレイスを進めました。
2. アプリケーション構成の特殊性によるIaCの再構築
次の課題は、アプリケーションの構成が他のプロジェクトと大きく異なることでした。通常は標準的なデプロイ手法が用いられますが、今回は特殊なデプロイ手順が必要であり、従来のIaCでは対応が難しいことが判明しました。
IaCの見直しと再設計
まず、既存のIaCテンプレートを見直しました。標準的なIaCではこのプロジェクトの要件に適合しない部分が多く、プロジェクト特有のIaCを再設計する必要がありました。この経験から、1つのIaCテンプレートで全てのプロジェクトに対応できるわけではないことを学びました。プロジェクトごとに異なる要件や制約があるため、柔軟性を持たせるためにはモジュール化されたテンプレートの採用が重要です。このアプローチにより、各プロジェクトに合わせたカスタマイズが可能となります。
しかし、今回はプロジェクトのタイムラインに追われ、十分なモジュール化を実現できませんでした。 今後は早い段階からプロジェクト固有の要件を把握し、モジュール化されたアプローチを設計に組み込むことが重要だと感じました。 これにより、将来的なプロジェクトでも効率的かつ柔軟に対応できる基盤を構築できると考えています。
このように、暫定的なAWS環境でのリプレイスや特殊なアプリケーション構成に伴う課題に対して、IaCの再構築やデプロイフローの最適化を行いました。 課題を明確に認識し、段階的な改善を行うことで、安定したサービス提供を実現しました。また、これらの改善は他のプロジェクトでも応用可能です。
以上、少しでも皆さんのお役に立てれば嬉しいです。
\\『真のユーザーファーストでマーケットを創造する』仲間を募集中です!! //
「少ない時間で多くの成果:期待値を揃える × 繰り返す」ことの重要性
こんにちは。クイックSREチームのみっちーです。
弊社SREチームでは円滑な事業推進に寄与することを目的として、
各プロダクトを横断して「サービス全体の品質を担保する」ことをミッションの1つとしています。
サービス全体の品質を担保するには、
いま現在10以上存在する各サービス特性や、その運営チームとも活発に会話をしながら進める必要があります。
お互いの期待値を合わせ、かつ共通の目標に向かって力を合わせることは難易度が高い反面、やりがいにも繋がると思っています。
さてそんな日々の中で、この記事を書こうと思うきっかけとなる「案件A」がありました。
案件Aは既存サービスのシステム更改作業で、
ユーザーの増加に伴って追加開発が必要となったものの、システム全体が陳腐化していて、開発効率が悪い状態を改善しようというものでした。
SREチームとサービス運営チームとの共同作業でしたが、
お互いの意思疎通がうまく行かず手戻りが多く発生し、結果としてリリース内容のそぎ落としや延期も起きてしまいました。
後日の振り返りで「大事なのはここだよね」という結論に至ったので、
この場を借りて発信していきたいと思います。
結論:(目的を理解した上でアウトプットの)期待値を揃える × マイルストーン毎に繰り返す
突然ですが「業務とは、あなたにとってどのようなものですか?一言で答えてください」と聞かれたら、 みなさんはどのように答えますか?
私であれば、 業務とは「目的達成のために、任された責任範囲においてゴールとスタートをつなぐ『道を整備する行為』だ」と答えます。
道を整備する上で、重要となるのは以下です。
責任範囲の明確化
- 期待値されていること : 何をしてほしくて、どこまでを任されているのか
- 期待値されていないこと: 何はしてほしくなくて、どこから先は任されていないのか
位置関係の明確化
- 目標 : ゴールはどこか
- 中間チェックポイント: マイルストーンはどこか
- 現在地 : スタートはどこか、いまどこか
持ち時間の明確化
- 期日 : いつまでにゴールする必要があるか
手段の明確化
- 選択肢 : どのような道をたどるか
- 選択肢の制限事項: 通れない道はあるのか
これらは、一言でいえば「アウトプットの期待値を揃える」ことだと私は思います。
これらがズレることで成果に繋がらないことや、手戻りが多く発生する原因となってしまいます。
また運よく成果に繋がったとしても、理由が整理できていないと次回以降の成果の再現性に繋がりません。
そういった意味でアウトプットの期待値を揃えることは、非常に重要だと考えています。
解釈の余地を極力減らす
人によって異なる意味で受け取られる表現は避けましょう。
例えば以下のような表現です。
- 追加費用が少しかかります。
- ➱ 追加費用が¥10万(税抜き)かかります。
- 今日中に資料を提出してください。
- ➱ 今日の18:00までに、私宛に、メールで資料を提出してください。
5W1Hを意識することで減らせます。
マイルストーンの重要性
スタートとゴールの距離が遠いケースでは、マイルストーンの設置をおすすめします。
設置することで「期待値に合っているか?」を確認する指標となります。
これにより以下のようなメリットが生まれます。
- 手戻りの発生回数が減る。
- 手戻りが発生しても、短時間で軌道修正できる。
- 手戻りが少ないので、トータルの所要工数が少なくて済む(予定通りに着地しやすい)
その一方でマイルストーンを設置しすぎると、チェック工数が増えるというデメリットが生まれます。
メリットデメリットを理解した上でうまくバランスをとりましょう。
マイルストーン設置のコツ
人によって様々なやり方があると思いますが、
コストパフォーマンス観点から、私は「二分探索法(バイナリサーチ)」に似た方法を使っています。
二分探索法とは…
要素が昇順(または降順)に並んでいる配列に対して高速に探索できるアルゴリズムです。
調べる範囲を半分に絞りながら探す方法なので、2つ(バイナリ)に分けて探索することから、バイナリサーチといいます。
1.まずスタートとゴールとの真ん中辺りに、大まかにマイルストーンAを設けます。

2.次にスタートとマイルストーンAとの真ん中辺りに、マイルストーンBを設けます。 3.同様に、スタートとマイルストーンBとの真ん中辺りに、マイルストーンCを設けます。

必要に応じて、各地点の中間にマイルストーンを更に追加してもいいでしょう。
そのうえで業務を開始するタイミングや各マイルストーン地点へ到達したタイミングを中心に、ステークホルダーとすり合わせをすると良いです。
なおスタート付近にマイルストーンを多く置くのは、ズレが小さいうちに修正できるチャンスを増やす狙いです。
お互いの意識が合ってくると、すり合わせる回数は減らせると思います。
最後に
業務は自分ひとりで行うわけではありません。 みんなで分担して、みんなで成果につなげていくものだと思います。
当然、自分が「これで完璧!」と思っても、
ステークホルダーからは「やり直し」と言われることもありますよね。
正直あまり気持ちのいいものではないと思いますし、できればやり直しはゼロにしたいですよね…
こういったことが起きないようにするには、。
発生のメカニズムを知って、その原因を地道に取り除くのが一番の近道ではないでしょうか。
最後までお読みいただきありがとうございます!
今回は「少ない時間で多くの成果:期待値を揃える × 繰り返す」ことの重要性についてお話しました。
少しでも、みなさまの日々の業務進行の助けになれば嬉しいです。
\\『真のユーザーファーストでマーケットを創造する』仲間を募集中です!! //
タスク管理をNotionへ移行した感想
こんにちは。みっきーです。
開発プロジェクトのタスク管理をBacklogからNotionへ移行して3ヶ月がたちました。今回は状況整理もかねて感想を書きたいと思います。移行方法は記載しないのでご注意ください。期待されている方は公式に解説があるのでそちらをお勧めします。
Notionに期待していたこと
- 階層構造でタスク管理がしたい
- 状況を見たい切り口で見れるようにしたい
- プロジェクトにまつわるレポートを作りたい
- 情報を一元管理したい
移行した結果
結論、期待していたことは実現できました。ものによって満足度がまちまちなのですが、順番に実現したことと感想を記載したいと思います。
階層構造でタスク管理ができた
Notionでタスク管理をするには2通りのやり方があります。
1つめは自分でタスク管理ツールになるようカスタマイズする方法。
2つめはテンプレートを選んで使う方法です。
今回は両方を掛け合わせ、テンプレートをベースにカスタマイズしています。
使ったテンプレートは・・・忘れてしまったので割愛します。
Notionが出しているプロジェクト&タスクをメインに何個か利用しています。
最終的に出来上がった構造はこちら
チームスペース ┗ リリースバージョン(マイルストーン) ┗ 案件親 ┗ 案件A ┗ 案件B ┗ タスク親(工程) ┗ タスク子(作業内容) ┗ タスク孫(レビュー) ┗ スプリント ┗ 以下同上
テンプレートの利用で案件とタスクの階層ができました。Notionでは情報が表管理されていてDBのように扱えます。上記の構造では、案件テーブル、タスクテーブルというように別れており、それぞれの中でも親子孫のように階層を作ることができます。
階層構造が作れるようになったのは便利なのですが、際限なく作ってしまうと管理が大変になるため、現在は以下のルールを定めて利用しています。
①案件は子案件まで作成OK 孫案件は作成NG
②タスクの親は工程で、子供に実際の作業ベースのタスクを作る
状況を見たい切り口で見れるようになった
プロジェクトの管理では見たい切り口が様々あると思います。Notionでは階層構造を利用することで実現できました。
プロジェクトの進行状況が知りたい
案件をリリースバージョンに紐づけることで、バージョンごとの進行状況を見ることができます。複数プロダクトの開発にも対応しているため、プロダクトxバージョンごとの状況も把握できます。

案件の進行状況が知りたい
どの案件がどんな状態かを把握するにはテンプレートのプロジェクトが便利でした。テンプレートは項目のカスタマイズや追加ができます。
※プロジェクト=案件として利用しています。
テンプレートをデフォルトのまま利用しても以下のことができます。
- ステータスを利用することでたくさんある案件の状態を確認できる
- 優先度と掛け合わせることで棚卸しなども行える
- 進行中のものは進捗率を見ることで進行度合いがわかる
※進捗率はタスクのステータスが集計されているため、タスクを最初から全量登録しておくのがポイントです。

タイムラインやカンバンなどでも状況を見ることができます。タイムラインでは、前後関係のある案件の開始終了日が変更された場合、自動で調整する機能があります。見やすいだけではなく、調整の手間も省けて大変助かっています。

タスク管理がしたい
案件ごとのタスクを見るにはテンプレートのタスクが利用できました。デフォルトで案件ごとのタスク一覧と全量の一覧とカンバン式が用意されています。加えて案件ごとにタスクを時系列で並べたガントチャートを、予実ごとに表示したり、担当者ごとに表示するビューを追加しています。
タスクは状況によって確認したい軸が変わるので、それごとにビューを用意できるのがとても便利です。
いちおしは「担当者ごとの実績をタイムラインで見れる」ビューです。人を跨いでの前後関係もわかるので、チーム開発をする上でとても重宝します。

その他
スプリントでタスクを管理できるものも作りました。社内システムを扱うプロジェクトに参画しているので、保守業務でヘルプデスクも行っています。
保守業務ではデータ更新やアカウント作成など細々したタスクが多く、計画を立てて実施する案件とは質が異なるため、同じ軸では管理が難しいと感じていました。
ここまでに紹介したリリースノート・案件・タスクを利用しつつ、状況はスプリントで見れるようにすることで、管理のしやすさと利用のしやすさを両立しています。
プロジェクトにまつわるレポートを作れた
まだまだ試行錯誤している最中なのですが、自動でレポート生成ができる状態にできました。
以下は手動レポートを廃止し、自動に切り替えたものです。
①保守業務 月ごとの完了件数/依頼件数
②案件も依頼と本プロジェクトの計画と両軸あるため、依頼元別の完了数やそれぞれの対応時間などを集計
③不具合 レベル別発生件数 検知工程別 発生原因別などを集計
毎月スプレッドシートに置き換えて集計していた作業がなくなり、いつでも状況を確認できるのが便利です。
情報を(一部)一元管理できた
こちらも試行錯誤中なのですが、プロジェクトのことはNotionを見れば全てわかる状態を目指して以下の整備を進めています。
①仕様書や設計書などの開発ドキュメント
②環境の利用状況 周知
③ノウハウ
④プロジェクトメンバーのこと
⑤プロジェクト外からの依頼
この中ですでに効果が出ているものとしては、②環境の利用状況 周知、④プロジェクトメンバー紹介、⑤プロジェクト外からの依頼があります。
②環境の利用状況
リモートPCや開発環境など共通で利用するものを毎回周知する運用があったのですが、把握しづらかったりチャットを追わないと分からないという地味に使いづらい状態が続いていました。こちらもNotion上に集約することで、状況の把握や周知が楽になりました。
例)リモートPC利用の共有ページ
使用開始・終了をクリックするだけで、誰がどのPCを使用中かわかります。

④プロジェクトメンバー紹介
メンバーの情報をいつでも見ることができるページも用意しました。「メンバー一覧」というテンプレートを使用しています。顔写真と名前と職種がセットになったカードが並ぶトップページがあり、そこから個人のページが開けるようになっています。
自プロジェクトに新しい方が入られた時や、関連プロジェクトの方の情報を共有するのに活躍しています。個性あふれる写真や紹介文が多く、眺めるだけでも楽しいです。
⑤プロジェクト外からの依頼
Slackや社内の業務依頼システムから直接Notionにタスクを作ることができました。
Slackはアプリを導入するだけで実現できます。社内の業務依頼システムは、もともとメールでお知らせを送る機能があったのでそちらを利用しています。受信したものをZapierで拾って、決まったルールでNotionに登録するよう設定しました。※設定方法は公式に記載があるのでそちらをご覧ください。
Backlogには標準搭載の便利な機能だったので、同じ感覚で利用できて一安心です。
これからやりたいこと
①仕様書や設計書などの開発ドキュメントと③ノウハウは、Googleドライブを利用しているので全てNotionに移すところまでは現状考えていません。ただ、仕様をNotionに書いておけばNotionAiを通して要約だったり、修正箇所の反映だったり、関連仕様を紐づけることが簡単にできるかもしれないなと思っています。そうなった場合はとても魅力的なので、ノウハウから少しずつ移行し、AIを問い合わせボットのようにできるか試そうと思います。
まとめ
タスク管理のみに特化したツールは他にもありますが、情報の一元管理やカスタマイズ性の点でとても便利なツールだと思いました。導入した結果、状況の見える化やタスク管理の精度アップ、定期作業を減らすなどプラスな効果が出ています。
試したいことや使いこなせていない箇所があるので、引き続き試していこうと思います。おすすめの使い方があったらコメントいただけると嬉しいです。
最後までお読みくださりありがとうございました。
\\『真のユーザーファーストでマーケットを創造する』仲間を募集中です!! //
バグとどう向き合っていくか
みなさん、バグ(不具合)、出してますか?
こんにちは。ソフトウェアエンジニアのたかにぃです。
これまで開発を通じて数多くのバグと遭遇してきました。
自身が実装者として出してしまったものもあればプロジェクトとして出してしまったものもありますが、いずれも「なんとか防げなかったものか…」と、いつも考えてしまいます。
バグを出してしまうと、すごく辛い気持ちになりますよね。
申し訳なさやら恥ずかしさやら情けなさで夜も眠れなくなったりします。
今回はシステム開発において、切っても切れない、でもお目にかかりたくない、そんなバグについて、普段考えていることをつらつらと言語化していきたいと思います。
ちなみに「バグを発生させない為の設計とは?」みたいな話は1ミリも出てきません。
期待していた方、ごめんなさい。
プロジェクトでのバグに対する取り組み
現在、私が所属しているプロジェクトでは、実際にリリースしてしまったバグや、テストなどで防げたもののヒヤリとしたバグなどを、スプレッドシートに蓄積していっています。
その上で、それぞれのバグに対して
- 不具合と対処した内容
- 検出タイミング
- 影響範囲
- 直接的/根本的な原因
- 本来検出したかった工程
- 予防/再発防止策
といった観点でまとめて、スプリントごとにエンジニア全員で振り返りを行なっています。
もちろん責任追及や犯人探しといった要素は排除し(※)、あくまでプロジェクト全体の責任と捉えて、今後のプロダクト品質向上やプロジェクトとしての開発品質向上に繋げるための取り組みになります。
(※)余談になりますが、これすごく大事なことなので、定期的&メンバーが加入するたびに啓蒙しています。
そうして蓄積されたバグたちを見ていくと、メンバーの意識啓発はもちろんのこと、実際に設計の見直しや運用フローの改善といった形で再発防止策を講じることができたものもありますが、現実的、かつ再現性のある形での再発防止が難しいものも少なくありません。
「システムが人の手で作り上げられる限り、絶対にバグが発生しないシステムは存在しない」とは言いますが、改めてバグを完全に防ぎ切ることは困難だと痛感させられます。
バグが及ぼす悪影響について
さて、そんな防ぐことが難しいバグではあるのですが、とはいえやっぱり出したくはないですよね。
この文章を読んでる方の中にバグなんて別に出してもいいや、と思ってる方は少ないと思いますが、なぜ出したくないのか?
整理のために、改めてバグが及ぼす悪影響について列挙していきましょう。
- ユーザー体験の悪化、顧客離れ
- ブランドイメージの損失
- 法的/訴訟リスク
- システム、企業、プロジェクト、エンジニア当人それぞれの信頼性の低下
- 修正/補填対応のためのコスト増加、それによる納期の遅延
- 品質管理コストの増大
- プロジェクトメンバーのモチベーションダウン、パフォーマンスの低下
パッと思いつくだけでもこれだけの悪影響があります。
ゾッとしますね!
企業として、システム開発者として、いちエンジニアとして「バグは出してはならぬ」と思わされます。
でも無くすことは難しい…
無くす/減らすための努力をし続けるのは当然として、その上でバグとどう向き合っていくか?が非常に大事だと考えています。
バグと向き合う上で大事にしていきたい考え
最初に予防線を張るようで恐縮なのですが、あくまで現時点での私個人としての考えであり、これが正解だというつもりはありません。異論反論あるかと思いますし、なんなら数年後に見たら自分自身で「何を言ってるんだコイツ」となるかもしれません。
その上で大事にしていきたい思いを綴らせていただきます。
エンジニアはバグを防ぐためだけに存在するわけではない
当たり前じゃんと思うかもしれませんが、バグの恐怖に負けそうになる度に意識している考えになります。
エンジニアは「テクノロジーの力を使って、社会や企業、ユーザーの課題や問題を解決し、生活や企業活動の質を向上させ、成長と発展を加速させる」そういった価値を生み出すことが役割だと思います。
その価値を生み出す為の一環としてバグを防ぐことが必要だと考えています。
何も生み出さなければバグが出ることは無いかもしれません。でもそれじゃダメですよね。
上記は極端な例ですが、目的の優先順位を間違えてはいけないと思います。
もちろんバグのリスクに目を瞑ってなんでもかんでもやれ、というつもりはありません。
そうなったら負けというか、本来はそうならないように設計、運用、開発体制を整えるべきではあるのですが、実際には「工数的に品質を担保できないため、断念する」ということはままあるとは思いますし、プロジェクトの現状を見据えた上でその判断をすることも非常に大切だと考えています。
その上で大事なのはリスクと天秤にかけつつ、勇気を持って価値を生み出すことだと思います。
ユーザーのためにバグを出さないという考えも当然大事です。
ですが、本来届けるべき価値の提供ができなかったり、遅れたりすることも、同様にユーザーに不利益を被らせていると考えるべきだと思います。
それら両面を考え抜くことが真のユーザーファーストに繋がるのではないでしょうか?
サービス品質水準の概念
これまで書いてきた通り、バグなんて出したくはありませんし出してはいけないと考えています。
ですが、あなたの手がけるサービスで、あるいは担当する1機能において、そのバグを防ぐこと(実際は防ぐ為の手段を講じ、実行すること)は何よりも優先すべきことでしょうか?
SLA(Service Level Agreement)とも通ずるものがありますが、どんなサービスにも適切な品質というものが存在すると思います。例えばですが、直接的に人命に関わるものやインフラなど影響範囲の極めて大きいシステムなんかは非常に要求される品質は高いと言えます。そうでないサービスが上記と同様の品質を追い求めてしまっては、それは過剰な品質保証になってしまい、本来生み出すべき価値を生み出せていないといえるかもしれません。
我々クイックが手がけるサービスは間接的にとはいえ、ユーザーの人生に影響を大きく及ぼし得るものばかりです。
超大事ですね!そのためサービスの品質が低くてもいいなんてことを思ってはいませんし、口が裂けても言えないと思っています。
ただし、だからこそユーザーの人生をより良くするために様々な価値を届けたいと考えていますし、また多くのユーザーに届けるためにも事業的にも成功していきたいとも考えています。
- 自分たちの扱うサービスは最低限どのぐらいの品質を担保しないといけないか?
- 過剰にバグを恐れていないか?
- 限られたリソースの中で取りうる品質と価値のバランスの落とし所はどこか?
どちらがユーザにとってより重要なのか?を考えつつ、日々のエンジニアリングに向き合うことが重要だと思います。
バランス、大事ですね。
最後に
バグについて日頃考えていることを言語化してみました。
余談となりますが、そもそも開発(実装)をせずに課題を解決することも立派なエンジニアリングですし、むしろ日々の業務でそういった判断をすることは重要だと考えています。ただ、本稿で伝えたいこととはズレるため、開発前提での内容とさせていただきました。
私自身品質やバグを軽視しているわけではありませんし、そう取られないよう注意したつもりではありますが、不快な感情を覚えた方もいるかもしれません。
ただ、賛成であっても反対であっても、バグに対する向き合い方を改めて考えるきっかけとしていただき、読んでくれた皆様の今後のエンジニアライフの一助となれば幸いです。
\\『真のユーザーファーストでマーケットを創造する』仲間を募集中です!! //
Laravel + Filament でサクッと管理画面を作る!
はじめに
こんにちは、ソフトウェアエンジニアのなししです。
業務において企画職もエンジニアもデータを気軽に確認、場合によっては作成/更新ができるシンプルな管理画面をサクっと作りたく、Laravel + Filament を使って実装を行いました!
今回はLaravel + Filament での管理画面の作成およびデータの参照にフォーカスして、実践した内容をまとめます!
前提
今回はFilament 2系を使って説明していこうと思います。
以下、前提条件です。
- PHP 8.0+
- Laravel 8.0+
- Livewire v2.0+
- テーブル作成 および Model作成済みであること
- Composerインストール済みであること
Filament とは?
Filament とは
- Tailwind
- Alpine.js
- Laravel
- Livewire
で構築された管理画面パッケージです。
データベースのモデルに基づいて、CRUD操作を自動生成してくれるため基本的なデータ管理機能を簡単に実装できます。
また既存のソースコードに影響なく、管理画面を自動生成してくれるので気軽に試せるのがとてもありがたいです!
やったこと
ダッシュボード の作成
まずは、インストール
$ composer require filament/filament
そして、ユーザ作成
$ php artisan migrate $ php artisan make:filament-user Name: > Email address: > Password: > Success! test@example.com may now log in at http://localhost/admin/login.
これだけで /admin/login にアクセスすると、ログイン画面が表示されます。
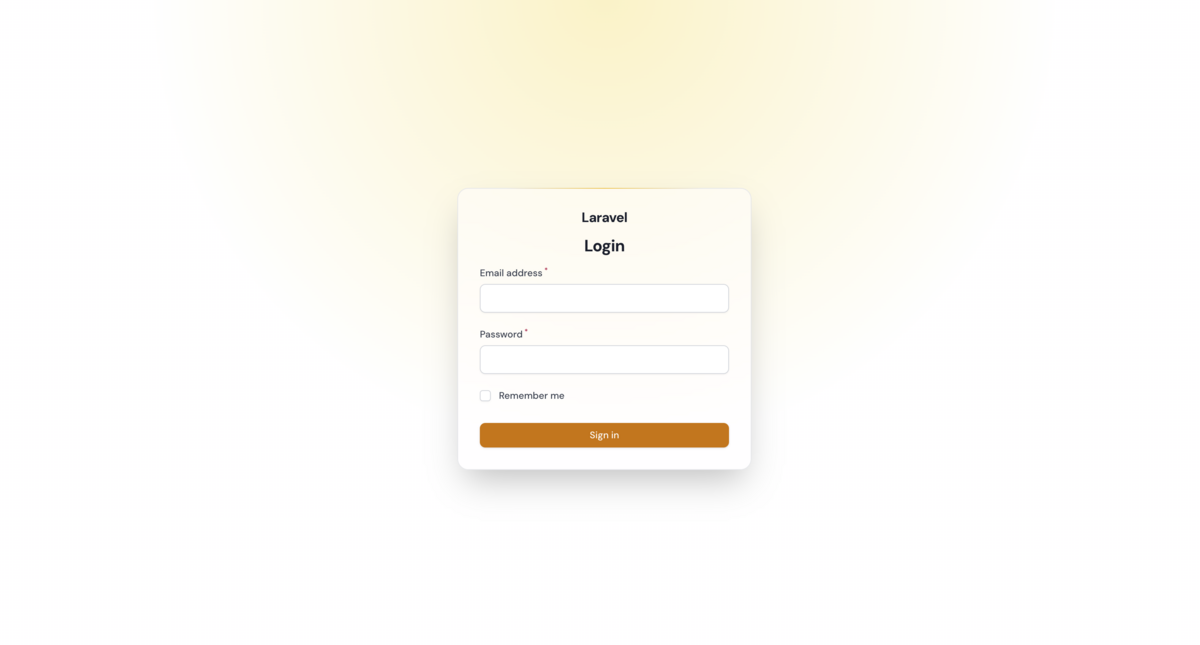
ログインするとダッシュボードが表示されます。
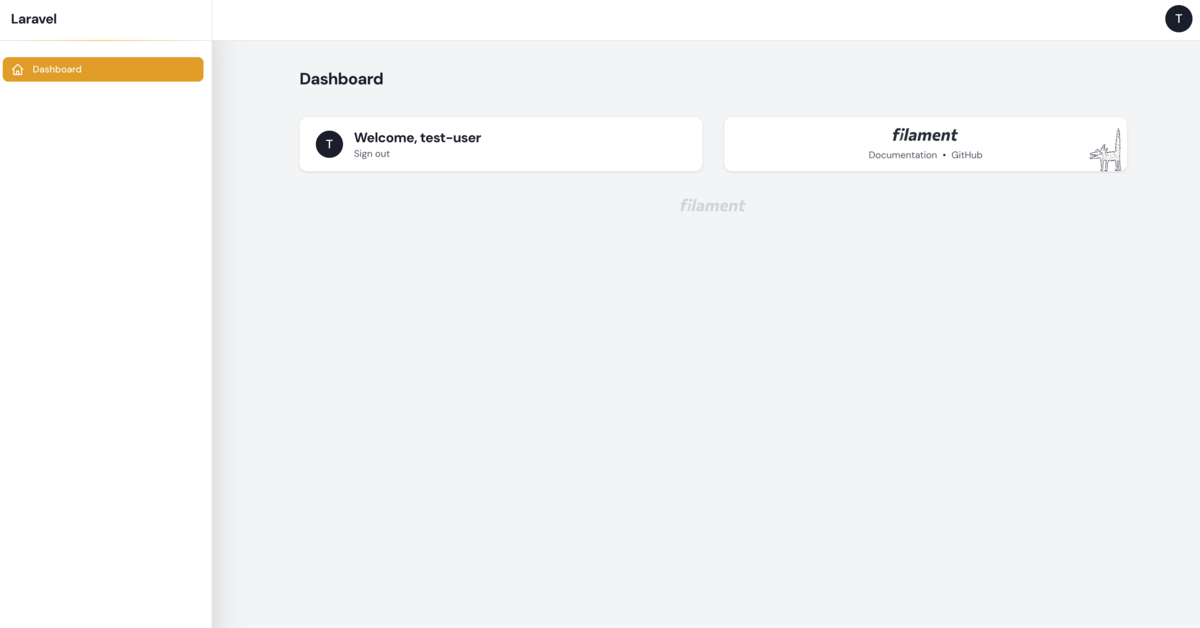
なんと、簡単!!!
ついでに英語なので、日本語に。
config/app.php
'locale' => 'ja',
Resource の作成
a_sampleというテーブルを例にとって説明します。
$ php artisan make:filament-resource ASample --generate
を実行すると
app/Filament/Resources 配下にFilamentのリソースが作成されます。
管理画面を更新すると A Sampleというページが作成され、a_sample テーブルのデータが表示されます。
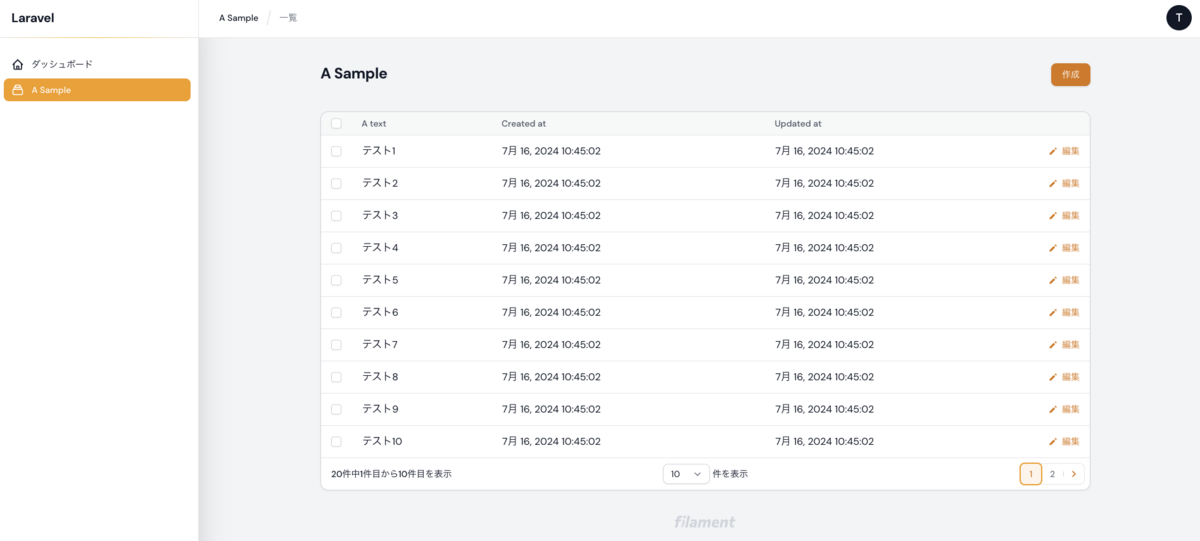
Modelの作成などは必要ですが、管理画面を作るにあたってはここまでノーコードです!便利!
閲覧したいデータや更新したいデータ等を要件に合わせてカスタマイズしたい場合は、自動生成されたリソースに手を加えることで対応可能です◎
子テーブルのデータを表示したい場合
A Sampleのページで子テーブルのデータを表示したいときも簡単です。
例えば a_sample テーブルに対して、b_sample のような子テーブルがあったとします。
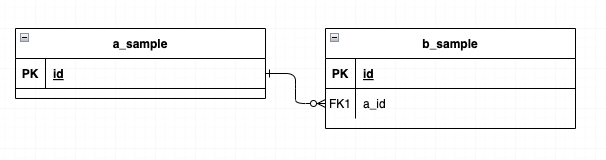
まずModel に関係性を示します。
app/Models/ASample.php
public function bSample():HasMany
{
return $this->hasMany(BSample::class, 'a_id', 'id');
}
自動で作成されたリソース( ASampleResource.php )にある table 関数に管理画面で表示したいカラムを指定します。
public static function table(Table $table): Table
{
return $table
->columns([
Tables\Columns\TextColumn::make('a_text'),
Tables\Columns\TextColumn::make('bSample.b_text')->label('Bテキスト'), // ここを追加
Tables\Columns\TextColumn::make('created_at')
->dateTime(),
Tables\Columns\TextColumn::make('updated_at')
->dateTime(),
])
->filters([
//
])
->actions([ // レコード単位で行いたいアクションを定義できる
Tables\Actions\EditAction::make(),
])
->bulkActions([ // 一括で行いたいアクションを定義できる
Tables\Actions\DeleteBulkAction::make(),
]);
}
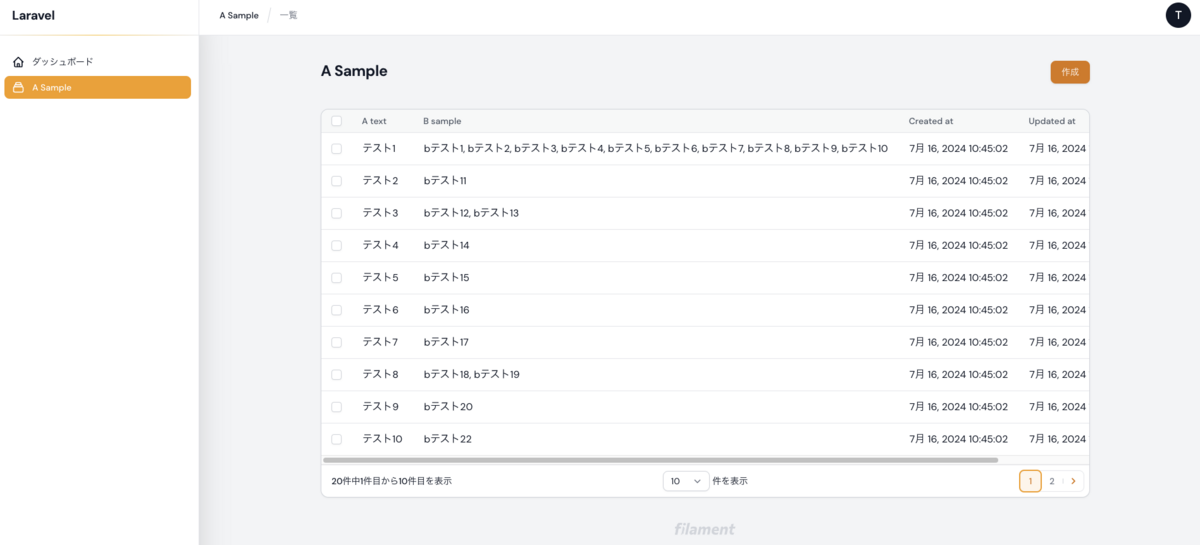
すると、A Sampleページに追加したカラム「Bテキスト」の内容が管理画面に表示されます。
a_sample と b_sample は 1対多の関係なので、複数ある場合は b_sample のデータがカンマ区切りで表示されています。
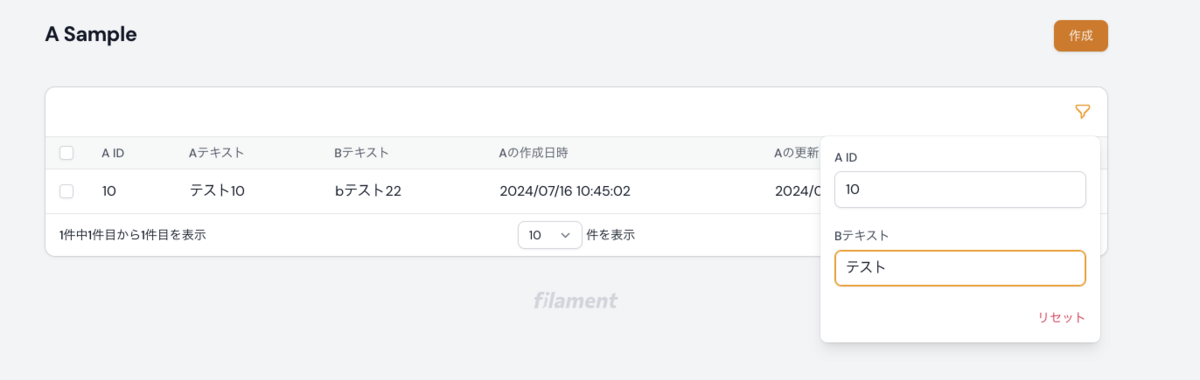
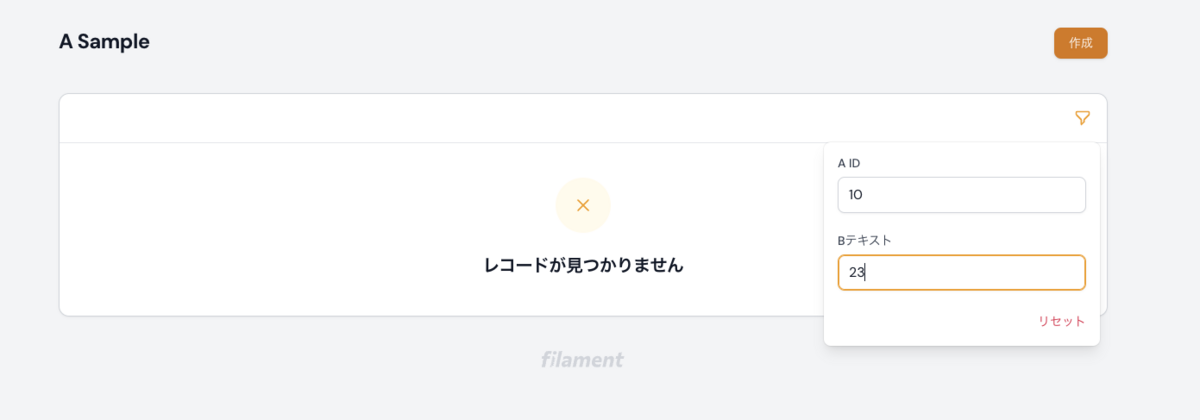
フィルタリングできるようにする
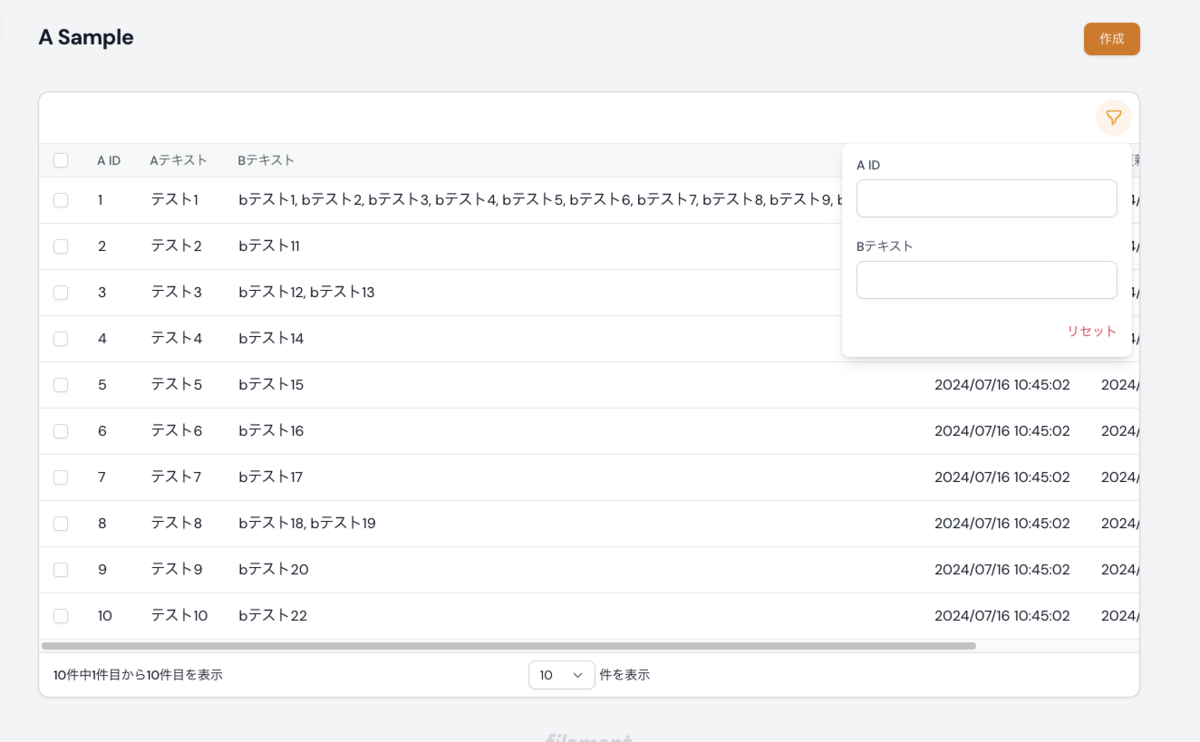
一覧画面でフィルタリングを行いたい場合は、下記のようにコードを追加します。
リレーション先のテーブルでフィルタリングを行いたい場合は whereHas を使ってあげましょう。
public static function table(Table $table): Table
{
return $table
->columns([
Tables\Columns\TextColumn::make('id')->label('A ID'),
Tables\Columns\TextColumn::make('a_text')->label('Aテキスト'),
Tables\Columns\TextColumn::make('bSample.b_text')->label('Bテキスト'),
Tables\Columns\TextColumn::make('created_at')->label('Aの作成日時')
->dateTime('Y/m/d H:i:s'),
Tables\Columns\TextColumn::make('updated_at')->label('Aの更新日時')
->dateTime('Y/m/d H:i:s'),
])
// ---- フィルターここから ----
->filters([
Tables\Filters\Filter::make('id')->label('A ID')
->form([
Forms\Components\TextInput::make('id')->label('A ID')
])
->query(function (Builder $query, $data) {
return $query
->when($data['id'], function (Builder $query, $searchWord) {
return $query->where('id', '=', $searchWord);
});
}),
Tables\Filters\Filter::make('b_text')->label('Bテキスト')
->form([
Forms\Components\TextInput::make('bSample.b_text')->label('Bテキスト')
])
->query(function (Builder $query, $data) {
return $query->whereHas('bSample', function ($query) use ($data) {
$query->where('b_text', 'like', '%' . $data['bSample']['b_text'] . '%');
});
}),
])
// ---- フィルターここまで ----
->actions([
Tables\Actions\EditAction::make(),
])
->bulkActions([
Tables\Actions\DeleteBulkAction::make(),
]);
}
すると、下記のように条件を指定できる入力フォームが表示されます。
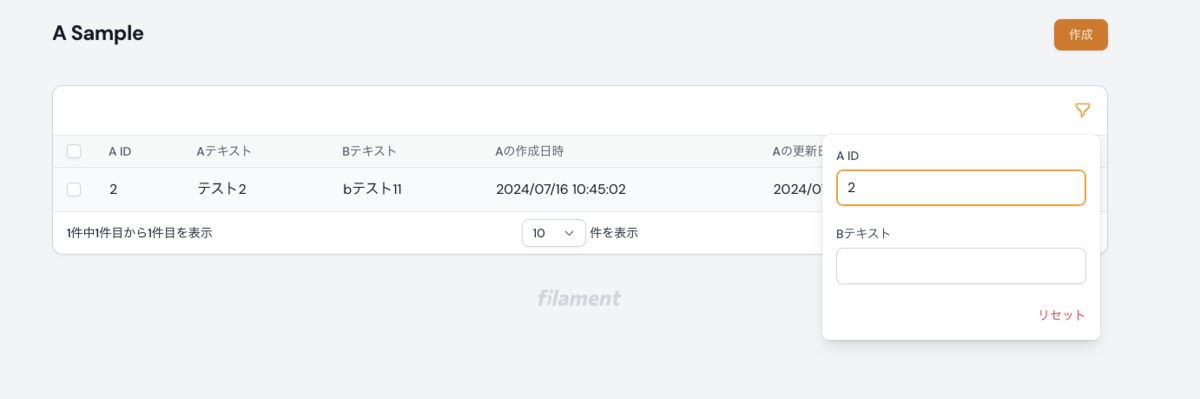
検索したい値を入力するとフィルタされます↓↓
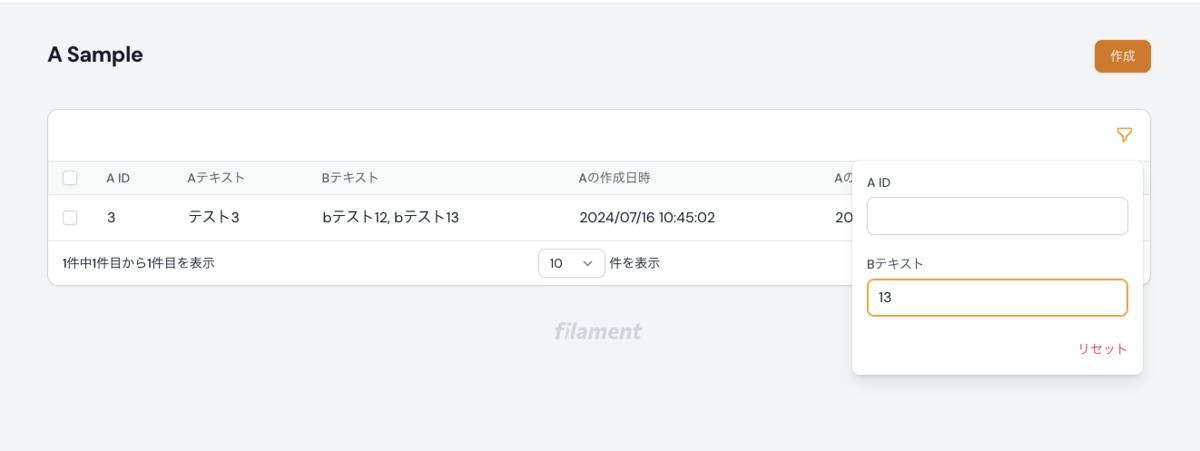
かけ合わせた検索も可能です↓↓
フィルタリングまでできるようになったところで、今回はここまでとしたいと思います。
インストールからフィルタリングの設定まで、1時間ほどで完了しました。
データの作成や更新も含めて、コマンドを実行するだけで管理画面が簡単に作成できたので、とても便利でした!
最後に
Filamentを利用してみて、お手軽にCRUD機能付き管理画面を作成したい場合、効果的で便利に使えるものだと思いました!
逆に下記に当てはまる場合は、Filamentではなく別の手段を検討したほうがよいと感じました。
- 大規模で高度な機能を持った管理画面が必要
- カスタマイズに関するドキュメントは充実していないため、必要に応じてソースコードを読むことが必要
- 完全にカスタムされたデザインや機能が必要な場合は対応しきれないことがある
- パフォーマンス懸念
- パフォーマンス改善するにもある程度制約がある中での対応となるため限界がある
利用する目的に合わせて、適切なものを検討できるといいですね!
誰かの参考になれば幸いです。
最後までお読みいただきありがとうございました!
\\『真のユーザーファーストでマーケットを創造する』仲間を募集中です!! //
応用情報技術者試験合格体験記(令和5年秋期)
はじめに
こんにちは、ちくわパンです。
少し前の話になりますが、2023年10月8日に応用情報技術者試験を受験し、一発合格しました!
今回はその合格体験記を共有したいと思います。
応用情報技術者試験とは
応用情報技術者試験は、情報処理技術者試験の一つで、情報処理推進機構(IPA)が主催する国家試験です。IT分野の中級レベルの知識と技能を問う内容が出題されます。

午前試験と午後試験に分かれており、午前は4択問題、午後は10分野のうち5分野を選択して回答する記述問題になっています。
筆者のバックグラウンド
筆者のバックグラウンドはこのような内容です。
- 理系学部卒(情報系ではない)
- 異業種からエンジニア転職して半年程度
- 本試験受験の約1年前に基本情報技術者試験取得済み
なぜ取得しようと思ったのか
基本情報技術者試験の記憶が新しいうちに受けたいと思っていたことと、エンジニア業務経験が浅いため幅広く体系的な知識を身につけたかったというのが主な理由です。
事前準備
情報収集
試験では情報収集が何より重要だと考えています。というのも、特に社会人は学習に充てられる時間が限られており、短い時間の中でいかに効率的に学習するかで結果が大きく変わってくるからです。
今回は、いろんな方の合格体験記を読み漁り、試験の特徴を掴んでいきました。この試験は個々人のバックグラウンドによって午後試験で選ぶべき問題が変わってくるため、バックグラウンドもかなり重要なポイントになります。
学習計画
学習期間と時間は下記の通りです。
- 学習期間:2ヶ月と1週間ほど(8月から学習開始)
- 平日の学習時間:30分〜1時間
- 休日の学習時間:2時間〜5時間
業務が忙しいタイミングでしたが、最後の1週間は業務時間を調整し、平日も午後試験の過去問を解く時間に充てました。
午前試験の対策
使った教材はこちらです

午後試験の対策
午後試験は選択問題なので、1年分の過去問を解いて選択する分野を決めました。
当日は必須分野含めて5分野の選択が必要ですが、当日分野によって難易度のばらつきがある可能性が高いので、余裕を持って下記7分野を学習しました。
- 情報セキュリティ(必須)
- プログラミング
- ネットワーク
- データベース
- 組み込みシステム開発
- 情報システム開発
- プロジェクトマネジメント
ネットワークは正直自信のある分野ではないですが、身につけたい知識だったことから選択しました。
使った教材はこちらです

解説が詳しいので、おすすめの一冊です。午前対策と同じく、最新2回分は取っておき、それ以前の5年分を繰り返し演習しました。
試験直前
時間を測って、通しで2年分の過去問を解きました。この時点で7割程度の正答率でした。
学習のポイント
午後試験の選択問題は全分野解いてみて考える
一般的におすすめとされる分野も、個々人のバックグラウンドによっては得点しづらい分野であることもあり得ます。
そのため、午後試験は全分野解いてみてから自身の得点しやすい分野を見極めました。
個人的には「プログラミング」「データベース」「情報システム開発」が得点しやすい分野でした。
反対に、「組み込みシステム開発」「プロジェクトマネジメント」は波が出やすい分野だったので、当日の難易度で取捨選択しようと考えていました。
多く解くより繰り返し解く
多く解いて解いたことがある問題を量産していっても「間違えた問題」が増えていくばかりです。試験当日、「解いたことはあるけど、正解はなんだっけ…」ということにもなり得ます。悲しいですよね…。そのため、「正解した問題」を増やしていくために、間違えた問題を正解するまで繰り返し解くことに重きをおいて学習していました。
午後試験は1分野20〜25分で解けるようにしておく
150分で5分野解く計算ですが、当日選択分野を決めるための時間も必要なので、早く解けるように練習していきました。
過去問は解答用紙を印刷して時間を測って解く
最低1年分は実施しておいた方がいいと思います。というのも、午前試験・午後試験ともに150分の試験時間に耐え抜かないといけなく、中々の集中力が必要になるため、慣れておいた方が良いからです。
また、エンジニアをやっていると、筆記用具を久しぶりに持ったという方もいらっしゃるかと思います。記述もあるため、紙に書く練習もやっていってよかったなと思いました。
試験当日
どんな試験にも言えることですが、朝は余裕を持って家を出ること。
また、試験会場が都心部でない方は、コンビニなど近くにないかもしれません。昼食を買っていくことをお勧めします。
午前試験
初見の単語が5個ほど出て焦りましたが、過去問の類似問題も多かったため、手応えはまあまあといったところでした。
午後試験への英気を養うために途中で退室して早めにお昼ご飯をとりました。お昼休憩は1時間しかないので、途中退出をおすすめします。
午後試験
データベースが易化したこともあり6分野解くことができました。
選択分野に関して、「エンジニアとしてプログラミングを捨てていいのか…?」と最後まで葛藤しましたが、自信があったプロジェクトマネジメントを含め、下記5分野を選択して終わりました。
- 情報セキュリティ(必須)
プログラミング(解いたが選択せず)- データベース
- 組み込みシステム開発
- 情報システム開発
- プロジェクトマネジメント
結果と振り返り
午前も午後も71点という、ギリギリな結果でした。(合格点は60点)
とはいえ合格です、やったー!
正直、業務に直結する知識は多くないですが、この学習によって下記の良い変化がありました。
- データベース・情報システム分野は、業務で得た知識と体系知識が結びついて理解度が高まった
- ネットワーク構築への苦手意識が以前より薄れた
- 他の分野に関しても、業務で直接触れる機会は少なくとも、理解が深まったことでシステム開発の全体像が掴みやすくなった
既にエンジニアとして何年も活躍されている方の受験は不要かなと思う一方、私のような駆け出しエンジニアにとっては良い学習機会となるためぜひおすすめしたい試験です。
今回の合格にあたり、会社からの受験費用の補助*1もあり、とても励みになりました。この経験を活かして、さらに高度な資格に挑戦し、スキルを一層高めていきたいと思います!
\\『真のユーザーファーストでマーケットを創造する』仲間を募集中です!! //
*1:※対象の試験に合格した場合、受験費用が戻ってくる制度
LaravelでSPA開発環境をサクッと作る
こんにちは、ソフトウェアエンジニアのやぎーです。
みなさんローカル開発環境の構築してますか。
ちょっとした検証や、思いつきでアプリを作ろうと思った時にサクッと作りたいことがあります。
しかし、設定やらエラーやらにつまづき、また時間ある時に...と挫折してしまう人も多いのではないでしょうか。
最新のLaravelでSailを使ってサクッと構築する手順を簡単にご紹介します。
環境
Laravel
PHPのフレームワーク。 バージョン11ではディレクトリ構成が変更されているのでご注意ください。
Inertia.js
フロントエンド・バックエンドを繋ぐためのアダプター。
Laravel用に調整されているが、Railsなどにも対応している。
React
JavaScript ライブラリ。
コンポーネントベースでSPA(Single Page Application)と相性が良い。
Vite
ビルドツール。
HMR(Hot Module Replacement)で修正分のみを適用してくれるため高速。
構築手順
Laravelインストール・起動
何はともあれ、まずはLaravel本体をインストールしていきます。
※Docker Desktopを使用します
プロジェクトを作成したいディレクトリに移動し、下記を実行します。
curl -s "https://laravel.build/inertia-react" | bash
本体のインストールが終わったら、sailを起動します。
cd inertia-react && ./vendor/bin/sail up -d
docker psでコンテナが起動していることを確認します。
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES d7a37822a7ba sail-8.3/app "start-container" 2 minutes ago Up 2 minutes 0.0.0.0:80->80/tcp, 0.0.0.0:5173->5173/tcp, 8000/tcp inertia-react-laravel.test-1 d2d689647a27 redis:alpine "docker-entrypoint.s…" 2 minutes ago Up 2 minutes (healthy) 0.0.0.0:6379->6379/tcp inertia-react-redis-1 e2960d4a5a25 mysql/mysql-server:8.0 "/entrypoint.sh mysq…" 2 minutes ago Up 2 minutes (healthy) 0.0.0.0:3306->3306/tcp, 33060-33061/tcp inertia-react-mysql-1 dd78e09916ab axllent/mailpit:latest "/mailpit" 2 minutes ago Up 2 minutes (healthy) 0.0.0.0:1025->1025/tcp, 0.0.0.0:8025->8025/tcp, 1110/tcp inertia-react-mailpit-1 d46113a1e304 getmeili/meilisearch:latest "tini -- /bin/sh -c …" 2 minutes ago Up 2 minutes (healthy) 0.0.0.0:7700->7700/tcp inertia-react-meilisearch-1 15c6cd20bd9f seleniarm/standalone-chromium "/opt/bin/entry_poin…" 2 minutes ago Up 2 minutes 4444/tcp, 5900/tcp inertia-react-selenium-1
起動が確認できたらマイグレーションを実行します。
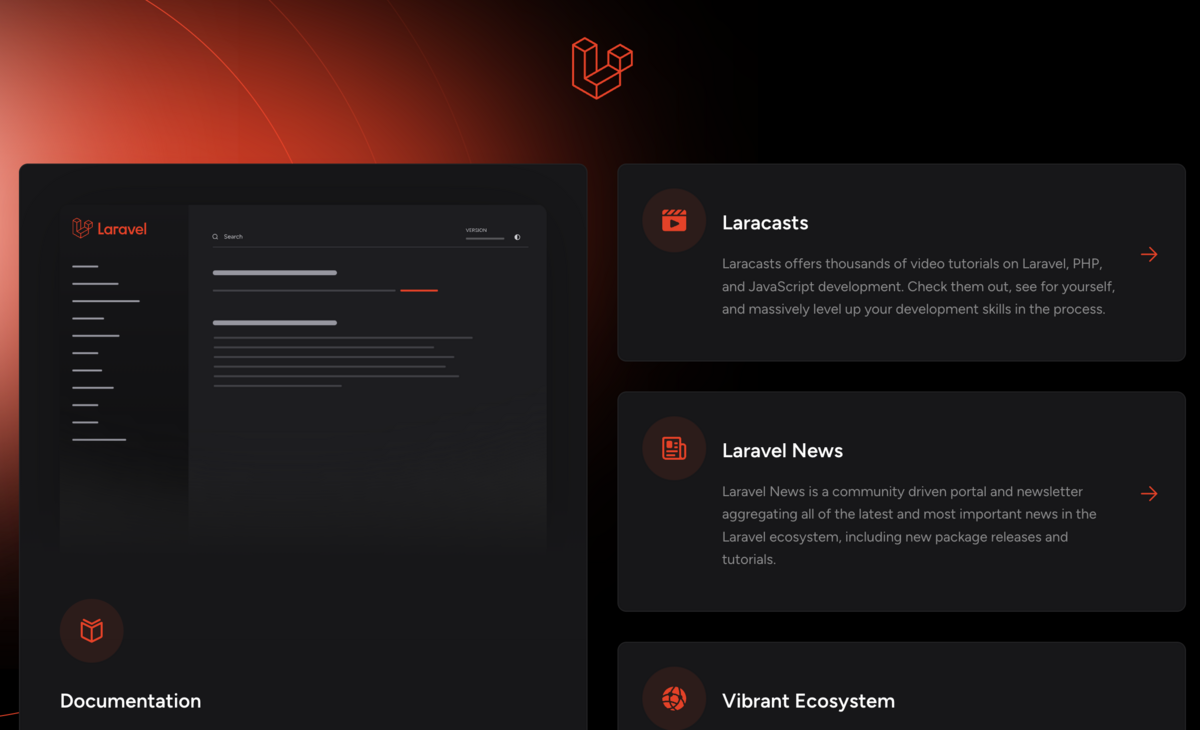
sail php artisan migrate
http://localhostにアクセスするとwelcome画面が表示できるようになります。
ライブラリのインストール ひとまず最低限必要なものだけインストールします。
# Reactとvite関連 sail npm install @vitejs/plugin-react @inertiajs/react react-dom # Inertia sail composer require inertiajs/inertia-laravel
ファイル・設定 SPAとして動かすために必要な設定を行います。
Middlewareを追加
sail php artisan inertia:middleware
webのルーティングでmiddlewareが適用されるよう設定。
Laravel11からMiddlewareの指定方法が下記のように変更されていますので注意。
// bootstrap/app.php
->withMiddleware(function (Middleware $middleware) {
$middleware->web(append: [
HandleInertiaRequests::class
]);
$middleware->api(prepend: []);
})
Inertiaを使うようにbladeを変更
<!-- resources/views/app.blade.php --> <!DOCTYPE html> <html> <head> <meta charset="utf-8" /> <meta name="viewport" content="width=device-width, initial-scale=1.0, maximum-scale=1.0" /> <title>Sample SPA</title> @viteReactRefresh @vite('resources/js/app.jsx') @inertia </head> <body style="margin: 0"> @inertia </body> </html>
Inertiaを使うようにapp.jsxを変更
// resources/js/app.jsx import "./bootstrap"; import { createInertiaApp } from "@inertiajs/react"; import { createRoot } from "react-dom/client"; createInertiaApp({ resolve: name => { const pages = import.meta.glob("./Pages/**/*.jsx", { eager: true }); return pages[`./Pages/${name}.jsx`]; }, setup({ el, App, props }) { createRoot(el).render(<App {...props} />); } });
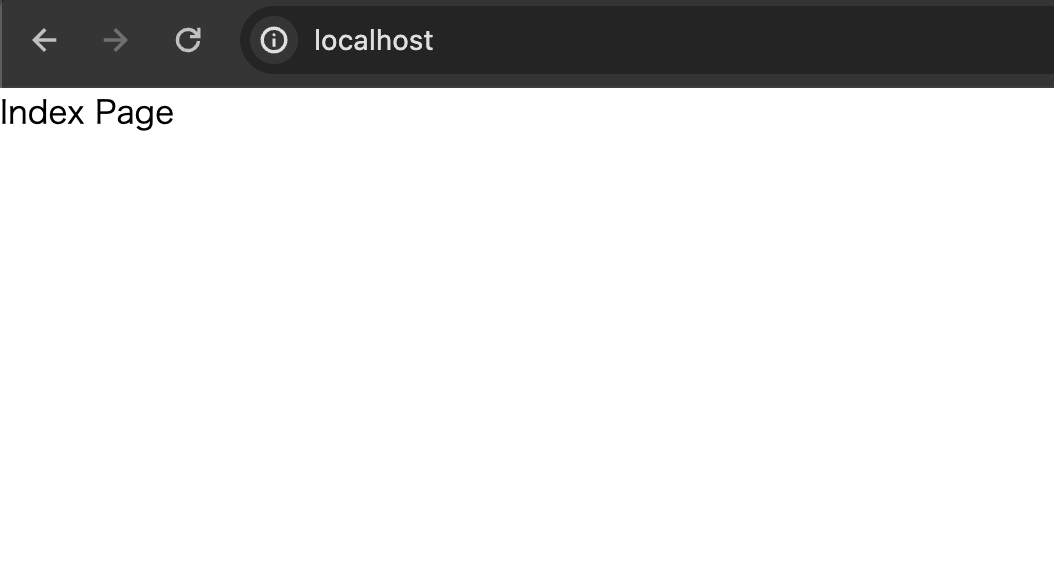
Pagesフォルダに表示するコンポーネントの作成
// resources/js/Pages/Index.jsx const Index = () => { return <>Index Page</>; }; export default Index;
ルーティング設定
// routes/web.php
Route::inertia('/', 'Index');
ビルドを実行
sail npm run dev
配置したコンポーネントが表示されていれば完了です。
Laravel・Reactの接続
通常ですと、ここからLaravelにAPIを実装しReactから取得を行う実装が必要になると思いますが、Inertiaを使うことでReactへの接続がbladeっぽくできるようになります。
コントローラー
// app/Https/Controllers/SampleController.php <?php namespace App\Http\Controllers; use App\Models\SampleLists; use Illuminate\Http\Request; use Inertia\Inertia; class SampleController extends Controller { public function index(Request $request) { // サンプルデータが入ったtableから10件取得 $sampleList = SampleLists::query() ->limit(10) ->get(); // Inertia::renderにコンポーネント名とデータを渡す return Inertia::render('Sample', [ 'sampleList' => $sampleList, ]); } }
ルート設定
// routes/web.php <?php use Illuminate\Support\Facades\Route; Route::get('/sample', 'App\Http\Controllers\SampleController@index');
受け取ったデータを一覧で取得するコンポーネント
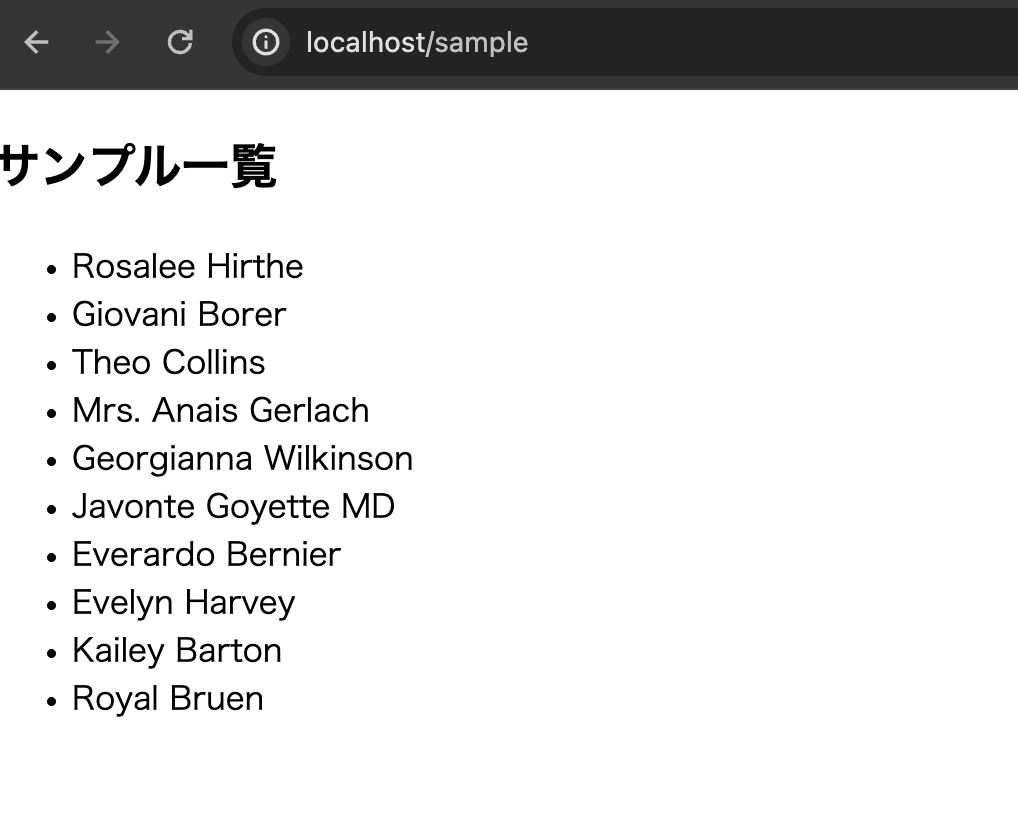
// resources/js/Pages/Sample.jsx // リスト作成 const createList = (list) => { return list.map(col => { return <li key={`key-${col.id}`}>{col.value}</li> }); } // Controllerで渡したデータをPropsで受け取れる const Sample = ({ sampleList }) => { return (<> <h2>サンプル一覧</h2> <ul>{createList(sampleList)}</ul> </>); }; export default Sample;
Laravelで渡したデータが表示されればOKです。
まとめ
細かな設定はさておき、ローカル動作環境を用意する手順としてはかなり手軽ではないでしょうか。
Inertiaの登場で、Laravel・React間の接続がとても簡単に作れるようになり、SPAでの開発を行うハードルは以前より確実に低くなっているように感じます。
日々更新される情報をキャッチし、よりスピード感のある開発をしていきたいと思います!
最後までお読みいただきありがとうございました。
\\『真のユーザーファーストでマーケットを創造する』仲間を募集中です!! //
Nuxt3 + Vuetifyでライトモード・ダークモードを切り替える機能を実装した話
こんにちは。新卒入社3年目ソフトウェアエンジニアのほっしーです。先日、プロジェクトを異動して業務でNuxt.jsとVuetifyを使い始めました。今回は業務でライトモード・ダークモードの切り替え機能を実装した際の話について記事にしました。
モード切り替え用stateの実装
まずはじめにライトモード・ダークモードの状態保持と切り替えを行うstateを作成しました。リアクティブな値(isDarkMode)を保持したいのですが、isDarkModeはコンポーネント間で共有する値のためrefではなくuseStateを使用しております。全体像は以下の通りです。
type ModeType = 'light' | 'dark'; export default function useMode() { const isDarkMode = useState('isDarkMode', () => false); const toggleMode = () => { isDarkMode.value = !isDarkMode.value; } const getCurrentMode = (): ModeType => { return isDarkMode.value ? 'dark' : 'light'; } return { toggleMode, getCurrentMode, } }
こちらのuseModeを各pageで呼び出してgetCurrentMode()から現在のテーマを取得します。ライトモード・ダークモードはtoggleMode()で切り替えます。
<template> <v-app :theme="getCurrentMode()"> <button @click="toggleMode"></button> </v-app> </template> <script setup> const { toggleMode, getCurrentMode } = useMode(); </script>
ComputedRefの導入
useModeをレビューに出したところ「現在のテーマを関数で取得する必要はあるのか?」という話になりました。isDarkModeとthemeで状態を二重に管理するのは不恰好だと思いgetCurrentMode()から現在のテーマを取得していたのですが、以下のような書き方にすることで状態はisDarkModeで管理しつつthemeでもリアクティブな値を保持できるようになりました。
type ModeType = 'light' | 'dark'; export default function useMode() { const isDarkMode = useState('isDarkMode', () => false); const toggleMode = () => { isDarkMode.value = !isDarkMode.value; } const theme: ComputedRef<ModeType> = computed((): ModeType => { return isDarkMode.value ? 'dark' : 'light'; }) return { toggleMode, theme, } }
各ページでは以下のように呼び出します。少しスマートになりましたね。
<template> <v-app :theme="theme"> <button @click="toggleMode"></button> </v-app> </template> <script setup> const { toggleMode, theme } = useMode(); </script>
useThemeの導入
二度目のレビューで「現在のテーマをisDarkModeで保持してるけどそもそもVuetifyで提供されてないのかな?」とご指摘をいただきました。私の調査不足だったのですが、VuetifyではuseThemeというAPIが提供されていました。こちらを「const theme = useTheme()」のように使うことで現在のテーマを取得することができます。上記の書き方を踏まえてuseModeを以下のように書き換えました。
export default function useMode() { const theme = useTheme(); const isDarkMode: ComputedRef<boolean> = computed((): boolean => { return theme.global.name.value === 'dark'; }) const toggleMode = (): void => { theme.global.name.value = isDarkMode.value ? 'light' : 'dark'; } return { toggleMode, } }
また、各ページで呼び出す際には「:theme="theme"」を書く必要がなくなりました。これでライトモード・ダークモードの状態保持と切り替えを行う機能は完成です。
<template> <v-app> <button @click="toggleMode"></button> </v-app> </template> <script setup> const { toggleMode } = useMode(); </script>
まとめ
今回はVuetifyでライトモード・ダークモードを切り替える機能を実装しました。もしこれから同じような機能を実装する方がいればお役に立てると幸いです。
\\『真のユーザーファーストでマーケットを創造する』仲間を募集中です!! // 919.jp
Mapped Typesを学んだのでアウトプット
こんにちは、ソフトウェアエンジニアのhamanokamiです!
最近のマイブームは某極麻婆豆腐で、辛いものを食べると腹痛が発生するリスクがあることを知りつつもついつい食べてしまいます。
さて今回はTypeScriptのMapped Typesについて書いていきます。
書こうと思った背景は、Software DesignのTypeScript特集でMapped Typesの記事内容がなかなか理解ができなかったのでMapped Typesの理解を促進させたいためです。
Mapped Typesとは?
Mapped Typesは「ある型から類似した別の型を生成」したいときに使用します。
TypeScriptの公式Docでは変更不可能な型から同じ構造で変更可能な型を生成する例が紹介されています。
// Removes 'readonly' attributes from a type's properties
type CreateMutable<Type> = {
-readonly [Property in keyof Type]: Type[Property];
};
type LockedAccount = {
readonly id: string;
readonly name: string;
};
type UnlockedAccount = CreateMutable<LockedAccount>;
この例だとCreateMutableがMapped Typesにあたります。
具体的に何をしているかというと、
- Genericsで受け取った型のプロパティ名をkeyof型演算子でユニオン型で返却(
Property in keyof Typeの部分) - 1で返却されたプロパティにreadonlyがある場合、readonlyを除く(
-readonlyの部分)
です。
よって、UnlockedAccount型は、
type UnlockedAccount = {
id: string;
name: string;
};
になります。
もしMapped Typeを使わない場合、
type LockedAccount = {
readonly id: string;
readonly name: string;
};
type UnlockedAccount = {
id: string;
name: string;
};
のように2つ型を定義する必要があり、もしAccountという情報にnicknameを追加したいとなった場合、LockedAccountとUnlockedAccountの両方にnicknameを追加する必要がありますが、Mapped Typeを使用した例ではLockedAccountのみで対応が済みます。
少し実用的なMapped Typesの使用例
今回は私の好きなアナログレコードの型からレコード情報を画面表示用文字列に変換して値を返却するメソッド型を生成をしてみます。
まずアナログレコードの型を用意します。
type Vinyl = {
artist: string;
title: string;
inch: number;
releaseYear: number;
};
このアナログレコード型の情報を画面表示用文字列に変換する関数式型の定義は下記になります。
type VinylFormatter = {
[Property in keyof Vinyl as `format${Capitalize<Property>}`]: (value: Vinyl) => string;
};
`format${Capitalize<Property>}`はTemplate Literal Typesを使用し、プロパティ名を例えばartistからformatArtistに書き換えています。
あとはVinylFormatter型を使った関数式を定義すればオッケー。
const vinylFormatter: VinylFormatter = {
formatArtist: (artist) => artist,
formatTitle: (title) => title,
formatInch: (inch) => `${inch}インチ`,
formatReleaseYear: (releaseYear) => `${releaseYear}年`,
};
このようにすればVinyl型にプロパティを追加したとき、画面表示用関数の対応漏れに気が付きやすくなります。※追加する必要性があるかは別ですが、、、
実際にどう動くかはPlaygroundを用意したので確認してみてください。 www.typescriptlang.org
VinylFormatterについて他の情報でも使用できそうな型なので、Genericsを使い汎用的に使用できるように拡張してみるとこのようなコードになります。
type Vinyl = {
artist: string;
title: string;
inch: number;
releaseYear: number;
};
type Cd = {
artist: string;
title: string;
discs: number;
releaseYear: number;
};
type ItemFormatter<Type> = {
[Property in keyof Type as `format${Capitalize<string & Property>}`]: (value: Type) => string;
};
const vinylFormatter: ItemFormatter<Vinyl> = {
formatArtist: (value) => value.artist,
formatTitle: (value) => value.title,
formatInch: (value) => `${value.inch}インチ`,
formatReleaseYear: (value) => `${value.releaseYear}年`,
};
const cdFormatter: ItemFormatter<Cd> = {
formatArtist: (value) => value.artist,
formatTitle: (value) => value.title,
formatDiscs: (value) => `${value.discs}枚`,
formatReleaseYear: (value) => `${value.releaseYear}年`,
};
こちらもPlaygroundを用意しているのでどうぞ。
さいごに
今回Mapped Typesと合わせて他の型再利用の方法についても理解が深まる良い機会になりました。引き続き他のTypeScriptの表現を学んでいこうと思います!
\\『真のユーザーファーストでマーケットを創造する』仲間を募集中です!! //